Modeling Topics from The Nobel Quran using Machine Learning & NLP

Have you ever wanted to learn more about Natural Language Processing (NLP), or been interested to learn how to train a Topic Modeling algorithm on a set of paragraphs to predict Topics from words and vice-versa? If your answer is yes, then hopefully this article will help you in your NLP learning journey.
In this article I am going to employ one of the contemporary algorithms published by Google researchers (Mikolov, Tomas, et al). “Distributed representations of words and phrases and their compositionality” (2013). The paper presents a word embedding model using a shallow Neural Network with one hidden layer that can be trained to reconstruct linguistic context of words.
To put this exercise in context, we are going to build an unsupervised learning algorithm to model topics from multiple verses from the Holy Book of Quran. To achieve that I will use a word2vec from Gensim library to configure, train and build a model by scanning the entire Quran Bible end-to-end, verse by verse, and word by word.
The algorithm uses a moving window of 7 words to scan verses and identify the co-occurrence of words based on their frequency of appearance as neighbors, to accomplish that I used different hyperparameters for word embedding window and learning rate.
Let’s dive into the code. I will explain the process backwardly this time to share the results first and make it more interesting to follow. So, let’s start with showing you some results of the algorithm; then, we will continue to know how the model was trained and deployed.
The following results was been generated from running the algorithm to find a context based on passing a single word as an input, which is a technique that is also called skip-gram method.

In the following examples, for each input word we will print a wordcloud that contains the top 80 words occurred in a similar context.
Example 1 — Passing `موسى` `moses` to the trained model
When the algorithm reads `Moses` as an input word word to our model, the algorithm acquired set of neighboring words (80) that was mentioned frequently in similar context. To mention few of them (Israel, Noah, Merry, Lot, John, Believers, Righteous, Tribes, etc). Again, the illustrated wordcloud below contains all of the words in the Quran that has the highest likelihood to appear around the word ‘Moses’ .

Example 2— Passing `جنة` `heaven` to the trained model

Prerequisites for building the project
- You need to have Python installed
- Download csv digital version of the Holy Quran
- Install (gensim) library to be able to use word2vec algorithm
- Install Natural Language Toolkit for Python (nltk) for download stop-words for Arabic, and use its Arabic word stemmer.
- Install bi-directional and arabic_reshaper libraries to support Arabic Text visualization
- Install (pandas) for loading and transforming data using Dataframe libraries
- Install (scikit) library to be able to visualize embedding using PCA algorithm
- Install (wordcloud) plugin to visualize word similarities in a form of cloud.
- All you need to do is to checkout the opensource python project and install dependencies from requirements.txt file
Explaining the Code & Machine Learning Pipeline
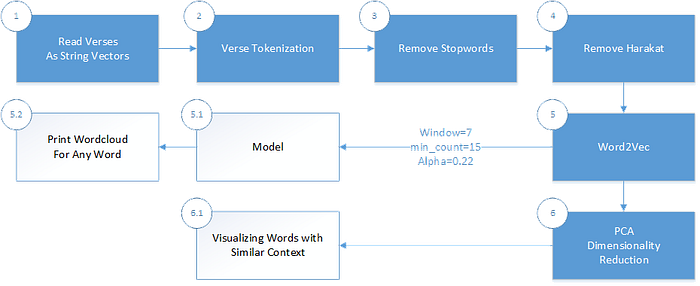
1. Reading the verses from a digitized version of the Quran as a Dataframe
# Download Arabic stop words Dataset from NLTK library
nltk.download('stopwords')# Extract Arabic stop words
arb_stopwords = set(nltk.corpus.stopwords.words("arabic"))# Initialize Arabic stemmer
st = ISRIStemmer()# Load Quran from csv into a dataframe
df = pd.read_csv('data/arabic-original.csv', sep='|', header='infer');
2. Verse tokenization
Breakout words from each verse and map each verse to a vector with set of corresponding word elements
# Tokinize words from verses and vectorize them
df['verse'] = df['verse'].str.split()3. Removing stop words to only select words with important meaning
# Remove Arabic stop words
df['verse'] = df['verse'].map(lambda x: [w for w in x if w not in arb_stopwords])4. Remove Harakat (Hyphenation)
Removing Harakat will help us reduce the combination of words that belong to the same verb.
# Remove harakat from the verses to simplify the corpus
df['verse'] = df['verse'].map(lambda x: re.sub('[ًٌٍَُِّۙ~ْۖۗ]', '', x))5. Start training and building the Word2vec model
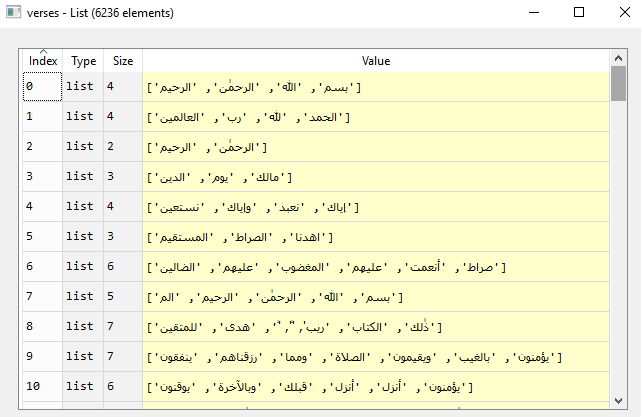
In the above figure you can see the last state of the List variable verses after the vectors passed to the filtration pipeline (Verse Tokinization, Remove Stop Words, & Remove Harakaat), so now verses list is in its last reduced form, and ready to be passed to our model for training.
Feel free to play around with hyperparameters, as they might impact the model either negatively or positively. The best parameters I personally found is used in the following code snippet. To understand the parameters more, please read the (Documentation). Note I am passing min_count=15, which dictate the model to ignore all of the words that has frequency count less than 15. Feel free to change it to increase or decrease the size of the generated vocabulary.
# You can filter for one surah too if you want!
verses = df['verse'].values.tolist()# train the model
model = Word2Vec(verses, min_count=15, window=7, workers=8, alpha=0.22)
Custom Model Visualization Library
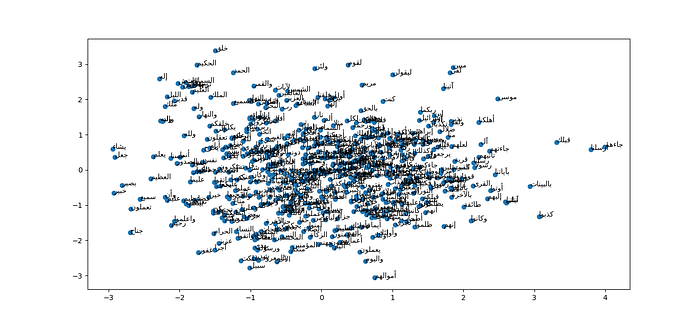
The model generated should contain the vector representation of all words we input. To be able to visualize the vector representation and see which word is closer in terms of co-occurrence and context to other words, we need to reduce the dimensions we have from a matrix of size (549x100)model[model.wv.vocab]. Accomplishing that requires dimensionality reduction algorithm like PCA, and the next snippet of code shows you exactly how I used PCA to reduce a vector representation with the size of (549x100) into (549x2) to be able to visualize the entire vocabulary in a (2-D) graph shown above.
# fit a 2d PCA model to the vectors
X = model[model.wv.vocab]
pca = PCA(n_components=2)
result = pca.fit_transform(X)# create a scatter plot of the projection
plt.scatter(result[:, 0], result[:, 1])
words = list(model.wv.vocab)# Pass list of words as an argument
for i, word in enumerate(words):
reshaped_text = arabic_reshaper.reshape(word)
artext = get_display(reshaped_text)
plt.annotate(artext, xy=(result[i, 0], result[i, 1]))
plt.show()
Code in Github

